정규표현식 정리
- #Udemy
- #regex
정규식 표현
/는 JS에서 정규식을 표현할 때 사용한다.
1/hey/
파이썬에서는 따옴표 앞에 붙이는 r을 사용한다.
1r'hey'
정량자
? | 0개 or 1개 | /he?y/ | hy hey |
|---|---|---|---|
+ | 1개 이상 | /he+y/ | hey heey heeeeey |
* | 0개 이상 | /he*y/ | hy hey heey heeeeey |
특수 문자
. newline(\n)을 제외한 모든 문자
특수문자를 매칭시키고 싶다면 \를 사용해야한다. (필요한 문자 : +?*.{}[]()^$)
정확한 길이만큼 매칭 {}
{1,3} : 길이 1 이상 3 이하
{3} : 정확히 길이 3
{3,} : 3번 이상
문자들의 모음 []
문자들의 모음을 만든다. 내부에서는 그냥 문자들을 나열한다.
[] 내에서는 정량자들의 법칙을 적용하지 않고 문자 그자체로 본다.
만약 16진수에 대한 정규표현식을 만든다면
1/[0123456789ABCDEF]+/
문자 범위
문자 범위는 [] 내에서 정의되어야한다.
범위를 생성하기 위해서는 -를 사용한다.
1/[0-9A-F]+/
부정 부호 [^ ]
[]안에 ^을 사용함으로써 문자 모음 안에 있는 문자들을 제외한다는 표현을 나타낼 수 있다.
^는 첫번째 문자여야한다.
1/[A-Z][^\.?!]+[\.?!]/
[A-Z] | 첫 글자는 대문자 영어로 시작해야한다. |
|---|---|
[^\.?!]+ | 중간 글자는 1개 이상 존재해야하며 . ? !가 아니어야 한다. |
[\.?!] | 마지막 글자는 . ? ! 중 1개여야한다. |
특수 토큰 \
\t | 탭문자 |
|---|---|
\n | newline |
\r | carrage return |
\b | vertical tab |
\f | form feed |
문자열 경계
^ | 정규식을 문자열의 처음에 고정 |
|---|---|
$ | 정규식을 문자열의 끝에 고정 |
문자 클래스
여러 문자를 대표하는 단일 토큰
\s | [\r\n\t\v\f{SPACE}] | 모든 공백 |
|---|---|---|
\S | [^\r\n\t\v\f{SPACE}] | 모든 공백 제외 |
\d | [0-9] | 숫자 |
\D | [^0-9] | 숫자 제외 |
\w | [0-9A-Za-z_] | 단어 문자 |
\W | [^0-9A-Za-z_] | 단어 문자 제외(비단어문자) |
\b | 단어 문자와 비단어 문자가 맞닿는 경계를 표현 문자열의 시작/끝도 포함 | |
\B | 단어 경계가 아님 양쪽이 모두 단어 문자 혹은 양쪽이 모두 비단어 문자 |
단어 경계 \b, \B
정규식에서 위치를 제공하지만 실제로 문자와 매칭되는 것은 아님.(^, $)
1/\bstem\b/23That rose has a lovely stem! //stem 매칭됨4Look at that solar system! //매칭되지 않음5
플래그
g | global | 중첩되지 않는 범위에서 가능한 한 많이 매치 / 없다면 한 번만 매치 |
|---|---|---|
m | multi-line | ^과 $가 라인 기준으로도 매치되도록 추가(원래는 newline을 포함해 전체를 하나의 문장으로 봤음) |
i | case-insensitive | 대소문자 구분 없이 매치 |
s | single line | .가 newline을 포함하도록 만든다. |
Greedy vs Lazy
JS는 모든 정량자가 Greedy이다.
정량자 뒤에 ?를 붙이면 lazy 정량자가 된다.
Lazy를 하면 가장 적은 매칭으로 유도된다.
예를 들어 gre??면 e?가 0~1인데 그 중 0으로 사용된다.
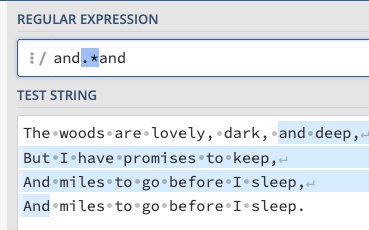
Greedy는 and부터 and 사이를 대소문자 구분없이 매칭하는 경우 중간에 and가 있음에도 이를 뛰어넘어 동작함.
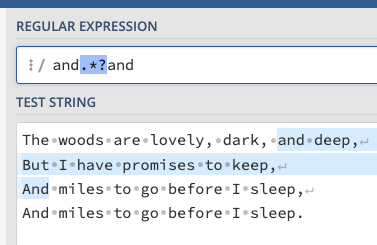
반대로 Lazy는 가장 짧은 문장을 선택함.
Lazy vs 부정 모음
/^[A-Z].+?[\.?!]+$/ vs /^[A-Z][^\.?!]+[\.?!]+$/
Lazy는 성능 문제가 있기 떄문에 모든 브라우저나 플랫폼에서 지원되는 사항이 아니지만, 부정 모음은 지원된다.
다중 문자 문자열(Multi Character String Tokens)
| 을 사용해 다중 문자 문자열을 만들 수 있다.
1/a|b|cad/
그룹 ()
괄호안에 있는 것은 그룹, 문자 모음과 달리 괄호 안에 있는 문자열을 인식하도록 한다.
1/I want a (kittens|puppy)/2/(kittens)+/ //그룹에 정량자를 사용할 수도 있다34//24 시간 표시5/([01]\d|2[0-3]):[0-5]\d/
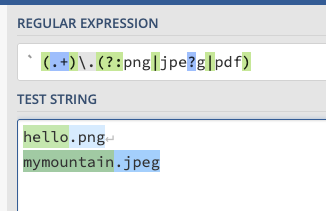
캡쳐(추출) 그룹
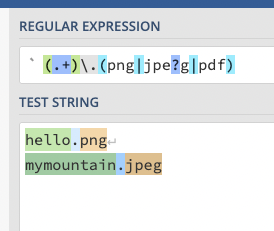
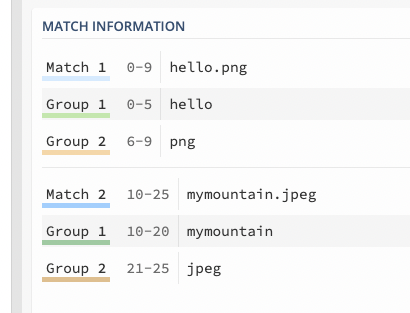
위 사진을 보면 정규 표현식의 소괄호()로 묶인 그룹을 기준으로
Group1, Group2로 그룹이 추출되는 것을 볼 수 있다.
각 그룹에는 번호가 부여된다. 이를 그룹 넘버라고 한다. 그룹 넘버는 순서대로 부여된다.
비캡쳐(비추출) 그룹 (?:)
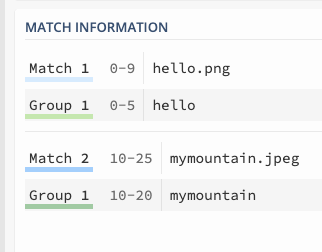
(?:)을 사용하여 해당 그룹을 비추출 그룹으로 만들 수 있다.
보면 확장자 부분이 원래는 Group2로 추출되었지만, 이제는 추출되지 않는 것이 보인다.
캡쳐 그룹은 저장되기 때문에 비캡쳐 그룹은 성능 최적화적인 면도 존재한다.
그룹 넘버 \1
그룹 넘버는 정규식 내부에서 참조용으로 사용할 수 있다.
1// html 태그 정규표현식2/<(\w+)>.*?<\/\1>/g // 앞선 첫 번째 그룹인 (\w+)를 받는다.
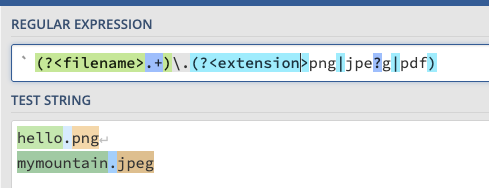
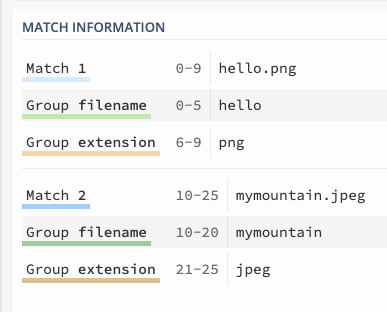
네임드 그룹 (?<이름>)
?<>로 추출할 그룹에 이름을 부여할 수 있다.
대입(대체) 그룹 $1
그룹을 참고할 때는 \를 사용하지만 그룹을 대체할 때는 $를 사용한다.
1const text = "Freeman, Morgan";2const result = text.replace(/(\w+),\s*(\w+)/, "$2 $1");3console.log(result); // "Morgan Freeman"
전방 탐색과 후방 탐색
전방/후방 탐색(lookaround)은 조건만 검사하고, 그 자체는 매칭 결과(캡처/치환 대상)에 포함되지 않는다.
| 전방 긍정 탐색 | {Match Pattern}(?=...) | … 패턴 앞에 원하는 패턴이 있어야함 |
|---|---|---|
| 전방 부정 탐색 | {Match Pattern}(?!...) | … 패턴 앞에 원하는 패턴이 없어야함 |
| 후방 긍정 탐색 | (?<=...){Match Pattern} | … 패턴 뒤에 원하는 패턴이 있어야함 |
| 후방 부정 탐색 | (?<!...){Match Pattern} | ... 패턴 뒤에 원하는 패턴이 없어야함 |
괄호 내에 있는 검사용 패턴을 기준으로 원하는 패턴이 있는지 검사.
괄호 안의 검사용 패턴은 정규식에 포함되지 않음으로 ^나 $를 사용하려면 괄호 안에서 사용해야한다.
1// 1) 전방 긍정 탐색: (검사용 패턴 ... ) "앞에" Match Pattern이 있어야 함2// 숫자(\d) "앞에" 있는 "abc"만 매치3/abc(?=\d)/g4// "abc1 abc" -> ["abc"]56// 2) 전방 부정 탐색: (검사용 패턴 ... ) "앞에" Match Pattern이 없어야 함7// "bar" "앞에" 있는 "foo"는 제외하고, 그 외 "foo"만 매치8/foo(?!bar)/g9// "foobar foo" -> ["foo"]1011// 3) 후방 긍정 탐색: (검사용 패턴 ... ) "뒤에" Match Pattern이 있어야 함12// "$" "뒤에" 있는 숫자만 매치13/(?<=\$)\d+/g14// "$100 200" -> ["100"]1516// 4) 후방 부정 탐색: (검사용 패턴 ... ) "뒤에" Match Pattern이 없어야 함17// 줄 시작(^) "뒤에" 있는 단어는 제외하고, 나머지 단어만 매치18/(?<!^)\w+/gm19// "Hello\nWorld" -> ["ello", "orld"]